Last 12 months have seen the emergence of Large Language Models (LLMs) at a breakneck speed. As more and more LLMs are being made available under open source and/or via apis, access has become easier also shifting the LLMs from domain of Data Scientists to everyone with basic understanding of software writing and api calling.
Large Language Models (LLMs) have shown powerful and emergent capabilities when it comes to the ways it can be put to use. At the most fundamental level, the way these LLMs are used is by way of providing a prompt to the LLM to do something specific and the LLM generates the output. The use case could vary from prompting the LLM to generate a blog with simple prompt like — “Write a 100 word blog about climate change” or to more complex use cases.
I will be using LLM as a more general term, though the code in this blog has been run mostly on OpenAI’s GPT3 model. The code used in the blog is available in this repo.
Let us now run our very first prompt with OpenAI’s GPT model.
Sentiment Classifier with a prompt like:
import os
import openai
# setup OPENAI Key
# if you do not have a key, signup and generate one here - https://platform.openai.com/signup
# you may need to use your credit card and then create an api key after that
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAAI-API-KEY>"
# Setup Search capability to be able to search using Google and various other services
# Visit this link and follow instructions to create an api key - https://serpapi.com/
# Free tier allows upto 100 searches per month which is more than sufficient for this demo purpose
os.environ["SERPAPI_API_KEY"] = "<YOUR-SERPAPI-API-KEY>"
prompt = '''
Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: "I loved the new Batman movie!"
Sentiment:
'''
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.0
)
print(response["choices"][0]["text"])
########OUTPUT########
PositiveNext, we look at a more complex “Chain of Thoughts” approach using a prompt which guides the model to output the answer to mathematical question by following intermediate steps required to calculate the answer.
prompt = '''
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roget started with 5 balls. 2 cans of 3 tennis balls each is
6 tennis balls. 5+6=11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to make lunch and
bought 6 more, how many apples do they have?
'''
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.0
)
print(response["choices"][0]["text"])
###MODEL OUTPUT###
A: The cafeteria started with 23 apples. They used 20 to make lunch,
leaving 3 apples. They bought 6 more, so they now have 9 apples.
The answer is 9.You can see that the same model can output simple to very complex answers based on the prompt. Therefore, how you design the prompt is very important. One could also keep building a history by combining previous interactions with the model with the new prompt to help the model retain context while completing the new prompt — a kind of chatbot style.
You could also feed a document, or scrapped website to provide the context and then ask the model questions to build a Q&A bot. You could ask the model to generate code to perform a task and then take the code output as additional history to ask a further question as a new prompt.
A lot of such new approaches have been formalised recently giving rise to a new discipline of “Prompt Engineering”. In this blog, I will cover a few of these approaches with code examples. This blog is being created as an introduction for the participants in the internal hackathon at Cloudcraftz Solution being run in March 2023.
The approaches I will cover are:
- Few Shot Prompting
- Chain of Thoughts Prompting
- Self Consistency Prompting
- ReAct — Reason and Act prompting
- PAL — Program aided Language Models
- MRKL Systems — Modular Reasoning, Knowledge and Language
- Self-Ask with Search
By no means this is an exhaustive list. I picked the approaches that I found interesting. Prompt Engineering is a fast evolving field with many new ideas being suggested on an almost daily basis. All the approaches that I will talk about revolve around keeping LLM model frozen, assuming that it cannot be finetuned. The only way allowed is to design the prompts with integration to external tools (e.g. python code executor, api call to some other system, database queries etc.) as intermediate steps.
For the code demo, I will use a library which in a short time has become very popular for Prompt Engineering with LLMs — LangChains
Few Shot Prompting
Let us start by talking about the most basic prompt style called “Few Shot Prompting”. The prompt under this can be divided into three subparts:
- Prefix: The instruction to the LLM — “Give the antonym of every input”
- Examples: a list of words with corresponding antonyms
- Suffix: The user input i.e. the word for which we want the model to output antonym
This is called “Few Shot” prompting as we are giving a few examples to the model as part of the prompt and telling the model to use that patten to complete the user query. There is no re-training of the model. The model remains static. We just construct the prompt in a specific way which induces the model to produce desired result with the help of a few examples.
from langchain import PromptTemplate, FewShotPromptTemplate
# First, create the list of few shot examples.
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
]
# Next, we specify the template to format the examples we have provided.
# We use the `PromptTemplate` class for this.
example_formatter_template = """
Word: {word}
Antonym: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_formatter_template,
)
# Finally, we create the `FewShotPromptTemplate` object.
few_shot_prompt = FewShotPromptTemplate(
# These are the examples we want to insert into the prompt.
examples=examples,
# This is how we want to format the examples when we insert them into the prompt.
example_prompt=example_prompt,
# The prefix is some text that goes before the examples in the prompt.
# Usually, this consists of instructions.
prefix="Give the antonym of every input",
# The suffix is some text that goes after the examples in the prompt.
# Usually, this is where the user input will go
suffix="Word: {input}\nAntonym:",
# The input variables are the variables that the overall prompt expects.
input_variables=["input"],
# The example_separator is the string we will use to join the prefix, examples, and suffix together with.
example_separator="\n\n",
)
# We can now generate a prompt using the `format` method.
print(few_shot_prompt.format(input="big"))
### OUTPUT THE PROMPT THAT WILL BE SENT TO LLM###
Give the antonym of every input
Word: happy
Antonym: sad
Word: tall
Antonym: short
Word: big
Antonym:
And now we can put this prompt to use to predict the antonyms for new words that we encounter.
from langchain.llms import OpenAI
from langchain.chains import LLMChain
# instantiate the openai default model - text-davinci-003
llm = OpenAI()
# set up a chain to be able to run the specific model with specific prompt
chain = LLMChain(llm=llm, prompt=few_shot_prompt)
# run chain for one input
chain.run("big")
### OUTPUT ###
" small"
# run chain again for another input
chain.run("sunny")
### OUTPUT ###
" cloudy"Another interesting example of few-shot is to use LLMs to generate synthetic data. An example of the same is given below:
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
{"word": "sunny", "antonym": "cloudy"}
]
example_formatter_template = """
Word: {word}
Antonym: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_formatter_template,
)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Add three other examples.",
input_variables=[],
)
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=few_shot_prompt)
print("### Model Output ###")
print(chain.predict())
######################################################
### Model Output ###
Word: fast
Antonym: slow
Word: generous
Antonym: stingy
Word: strong
Antonym: weakWhile I have used the langchain library, you could construct the prompt in any manner that you prefer and directly call OpenAI’s api using the python library provided by OpenAI. Or you could use langchain library which is a nice one to work with.
Give it a try with your own prompt and examples and tweak them till you start getting the desired results.
Chain of Thought Prompting(CoT)
Chain of Thought Prompting came from Google team early last year. It is a very simple idea but one with a lot of power packed in it. The idea adds intermediate steps of reasoning leading to final solution for each of the few-shot examples and then asks the model to solve another user defined problem. The LLM will use the patterns of examples provided to complete the prompt by giving the intermediate reasoning steps and final answer for the unsolved problem. The paper shows that such an approach increases the correctness of the answer significantly over the naïve few-shot approach. An example of the same is given below:
template = """
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:"""
prompt = PromptTemplate(
input_variables=[],
template=template
)
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=prompt)
print("### Model Output ###")
print(chain.predict())
### MODEL OUTPUT ####
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.Next we take a look at Self-consistency Prompting. It is an extension of the CoT wherein decoding (running the model/generating the output from LLM) is done multiple times using the same CoT prompt. The most consistent/frequent answer is chosen as the final output. In theory the candidate outputs from the model need to be weighed by the probability of generating the path of reasoning and the answer. The paper, however, shows an easy and almost equally good approach — that of simple majority voting of answers. Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer. A simple example demonstrating this approach is given below:
# Table 17 from self-consistency paper - https://arxiv.org/pdf/2203.11171.pdf
template = """
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted. So, they must have planted 21 - 15 = 6 trees. The answer is 6.
....
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent 5
Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister?
A:
"""
prompt = PromptTemplate(
input_variables=[],
template=template
)
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=prompt)
print("### Model Output ###")
for i in range(3):
print(f"Output {i+1}\n {chain.predict()}")
### Model Output ###
Output 1
When I was 6, my sister was half my age. This means that my sister was 6/2 = 3 years old.
Now I'm 70, so my sister is 70 - 3 = 67 years old. The answer is 67.
Output 2
When I was 6 my sister was half my age. That means when I was 6 my sister was 6/2 = 3.
That means my sister is now 70 - 3 = 67 years old. The answer is 67.
Output 3
At the time when I was 6 my sister was half my age. That means she was
6/2 = 3. Now I am 70, so she is 70/2 = 35. The answer is 35.
As you can see 67 appears twice and 35 once. The model gives the path of reasoning it followed to arrive at the answer. Using the majority voting, we can go with 67 as the correct answer. However, please do note that when you run it again, you may see 35 or some other number as the most frequent answer. Naive use of LLMs with CoT and self reasoning improves the accuracy but still it offers no guarantee.
There are other ways to integrate LLMs with external tools to solve problems which require fact checking, specific information retrieval like in-house accounting system or some specific numerical calculations.
ReAct: Synergizing Reasoning and Acting in Language Models is an approach which integrates task specific actions which could be doing some calculation, searching the web and/or querying a database/datastore. The outcome of such an action generates an observation which then leads to a next cycle of Thought->Action->Observation. The model goes through multiple such cycles finally producing the answer. The approach as illustrated in the paper is given below:
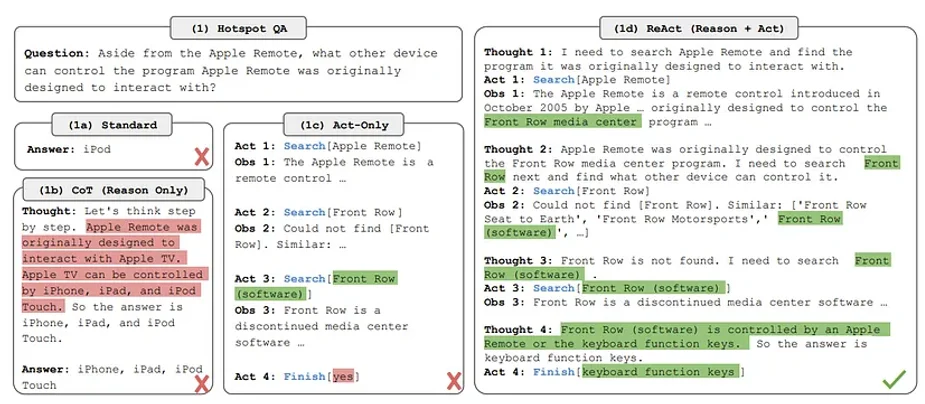
We define a set of tools that can be used in the Action step. In our case we will use the ability to search and lookup within wikipedia. There is a python library wikipedia which provides the functionality to search the wikipedia. This is further wrapped around by DocstoreExplorer from langchain which further enables the lookup capability within the documents returned by search. A code of using ReAct with langchain is given below:
from langchain import OpenAI, Wikipedia
from langchain.agents import initialize_agent, Tool
from langchain.agents.react.base import DocstoreExplorer
docstore=DocstoreExplorer(Wikipedia())
tools = [
Tool(
name="Search",
func=docstore.search,
description="Try to search for wiki page."
),
Tool(
name="Lookup",
func=docstore.lookup,
description="Lookup a term in the page, imitating cmd-F functionality"
)
]
llm = OpenAI(temperature=0, model_name="text-davinci-003")
react = initialize_agent(tools, llm, agent="react-docstore", verbose=True)
question = "What profession does Nicholas Ray and Elia Kazan have in common?"
react.run(question)And here is the MODEL OUTPUT
> Entering new AgentExecutor chain... Thought 1: I need to search Nicholas Ray and Elia Kazan, find their professions, then find the profession they have in common. Action 1: Search[Nicholas Ray] Observation 1: Nicholas Ray (born Raymond Nicholas Kienzle Jr., August 7, 1911 – June 16, 1979) was an American film director, screenwriter, and actor best known for the 1955 film Rebel Without a Cause. He is appreciated for many narrative features produced between 1947 and 1963 including They Live By Night, In A Lonely Place, Johnny Guitar, and Bigger Than Life, as well as an experimental work produced throughout the 1970s titled We Can't Go Home Again, which was unfinished at the time of Ray's death. Ray's compositions within the CinemaScope frame and use of color are particularly well-regarded and he was an important influence on the French New Wave, with Jean-Luc Godard famously writing in a review of Bitter Victory, "... there is cinema. And the cinema is Nicholas Ray." Thought 2: Professions of Nicholas Ray are director, screenwriter, and actor. I need to search Elia Kazan next and find his professions. Action 2: Search[Elia Kazan] Observation 2: Elia Kazan (; born Elias Kazantzoglou (Greek: Ηλίας Καζαντζόγλου); September 7, 1909 – September 28, 2003) was an American film and theatre director, producer, screenwriter and actor, described by The New York Times as "one of the most honored and influential directors in Broadway and Hollywood history".Born in Constantinople (now Istanbul), to Cappadocian Greek parents, his family came to the United States in 1913. After attending Williams College and then the Yale School of Drama, he acted professionally for eight years, later joining the Group Theatre in 1932, and co-founded the Actors Studio in 1947. With Robert Lewis and Cheryl Crawford, his actors' studio introduced "Method Acting" under the direction of Lee Strasberg. Kazan acted in a few films, including City for Conquest (1940).His films were concerned with personal or social issues of special concern to him. Kazan writes, "I don't move unless I have some empathy with the basic theme." His first such "issue" film was Gentleman's Agreement (1947), with Gregory Peck, which dealt with antisemitism in America. It received eight Oscar nominations and three wins, including Kazan's first for Best Director. It was followed by Pinky (1949), one of the first films in mainstream Hollywood to address racial prejudice against African Americans. A Streetcar Named Desire (1951), an adaptation of the stage play which he had also directed, received twelve Oscar nominations, winning four, and was Marlon Brando's breakthrough role. Three years later, he directed Brando again in On the Waterfront, a film about union corruption on the New York harbor waterfront. It also received 12 Oscar nominations, winning eight. In 1955, he directed John Steinbeck's East of Eden, which introduced James Dean to movie audiences. A turning point in Kazan's career came with his testimony as a witness before the House Committee on Un-American Activities in 1952 at the time of the Hollywood blacklist, which brought him strong negative reactions from many friends and colleagues. His testimony helped end the careers of former acting colleagues Morris Carnovsky and Art Smith, along with the work of playwright Clifford Odets. Kazan and Odets had made a pact to name each other in front of the committee. Kazan later justified his act by saying he took "only the more tolerable of two alternatives that were either way painful and wrong." Nearly a half-century later, his anti-Communist testimony continued to cause controversy. When Kazan was awarded an honorary Oscar in 1999, dozens of actors chose not to applaud as 250 demonstrators picketed the event.Kazan influenced the films of the 1950s and 1960s with his provocative, issue-driven subjects. Director Stanley Kubrick called him, "without question, the best director we have in America, [and] capable of performing miracles with the actors he uses.": 36 Film author Ian Freer concludes that even "if his achievements are tainted by political controversy, the debt Hollywood—and actors everywhere—owes him is enormous." In 2010, Martin Scorsese co-directed the documentary film A Letter to Elia as a personal tribute to Kazan. Thought 3: Professions of Elia Kazan are director, producer, screenwriter, and actor. So profession Nicholas Ray and Elia Kazan have in common is director, screenwriter, and actor. Action 3: Finish[director, screenwriter, actor] > Finished chain. 'director, screenwriter, actor'
You can also checkout the code from the original repo accompanying the paper here. This can be run with just openai library without using langchain.
Next we take a look at PAL: Program-aided Language Models. While LLMs are good at step-by-step breaking down of a math or logic problem via CoT approach, LLMs often make math and logical mistakes even when problem is decomposed correctly. In PAL the intermediate reasoning steps are generated as programs which are offloaded to a solution step. Solution Step runs these intermediate programs using a runtime such as python interpreter. Let us use Python based interpreter with LLM to solve a word problem in math.
from langchain.chains import PALChain
from langchain import OpenAI
llm = OpenAI(model_name='code-davinci-002', temperature=0, max_tokens=512)
pal_chain = PALChain.from_math_prompt(llm, verbose=True)
question = "Jan has three times the number of pets as Marcia. Marcia has two
more pets than Cindy. If Cindy has four pets, how many total pets do the three
have?"
pal_chain.run(question)The PAL based LLM model produces a program to solve the problem, which is then offloaded to python interpreter to solve the problem
> Entering new PALChain chain...
def solution():
"""Jan has three times the number of pets as Marcia. Marcia has two more pets than Cindy. If Cindy has four pets, how many total pets do the three have?"""
cindy_pets = 4
marcia_pets = cindy_pets + 2
jan_pets = marcia_pets * 3
total_pets = cindy_pets + marcia_pets + jan_pets
result = total_pets
return result
> Finished chain.
'28'Behind the scene this is very simple. In the prompt to LLM, we provide a bunch of problems with example code. The LLM completes the output using the few-shot approach and this output is then handed off to a python interpreter to run. The Prompt given to the LLM looks something like this:
PROMPT
=======
Q: Olivia has $23. She bought five bagels for $3 each. How much money does
she have left?
# solution in Python:
def solution():
"""Olivia has $23. She bought five bagels for $3 each. How much money
does she have left?"""
money_initial = 23
bagels = 5
bagel_cost = 3
money_spent = bagels * bagel_cost
money_left = money_initial - money_spent
result = money_left
return result
... many more such examples....
Q: There are 15 trees in the grove. Grove workers will plant trees in
the grove today. After they are done, there will be 21 trees.
How many trees did the grove workers plant today?
# solution in Python:
def solution():
"""There are 15 trees in the grove. Grove workers will plant trees
in the grove today. After they are done, there will be 21 trees.
How many trees did the grove workers plant today?"""
trees_initial = 15
trees_after = 21
trees_added = trees_after - trees_initial
result = trees_added
return result
Q: Jan has three times the number of pets as Marcia. Marcia has two
more pets than Cindy. If Cindy has four pets, how many total pets do the three
have?
# solution in Python:Next in the line is MRKL Systems where MRKL stands for Modular Reasoning, Knowledge and Language. It is fairly similar to ReAct in terms of combining LLMs with external tools. ReAct came a few months after MRKL paper and I would now go for ReAct approach. Let us look at one such example from langchain library documentation. In ReAct style, the model will reason about a problem to act using one of the three tools a) Google Search via SerpApi ; b) Query a database for some information and c) Calculator implemented via generation of python code from natural language description of the calculation using a LLM and running the generated code through a python REPL.
Let us look at a case where we ask our system to find a famous actor’s girlfriend, find her current age and finally do some calculation with that age:
“Who is Leo DiCaprio’s girlfriend? What is her current age raised to the 0.43 power?”
We will first setup the MRKL system as below:
from langchain import LLMMathChain, OpenAI, SerpAPIWrapper, SQLDatabase, SQLDatabaseChain
from langchain.agents import initialize_agent, Tool
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events. You should ask targeted questions"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
Tool(
name="FooBar DB",
func=db_chain.run,
description="useful for when you need to answer questions about FooBar. Input should be in the form of a question containing full context"
)
]
mrkl = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)And now we run ths system asking the question
mrkl.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")The output produced by mrkl is as given below. You can see the steps the system goes through to answer this query:
> Entering new AgentExecutor chain...
I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.
Action: Search
Action Input: "Who is Leo DiCaprio's girlfriend?"
Observation: Camila Morrone
Thought: I need to calculate her age raised to the 0.43 power
Action: Calculator
Action Input: 22^0.43
> Entering new LLMMathChain chain...
22^0.43
```python
import math
print(math.pow(22, 0.43))
```
Answer: 3.777824273683966
> Finished chain.
Observation: Answer: 3.777824273683966
Thought: I now know the final answer
Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.777824273683966.
> Finished chain.
"Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.777824273683966."Now we know that Camila Morrone may no more be Leo DiCaprio’s girlfriend. This goes to show that even after integration with external search, there is a chance that the model produces wrong output. When you design such system, your design must take into account that no ML driven system will even be 100% and your design must provide a graceful backoff with some kind of expectation setting with the user of such a system.
Let us try another example, this time finding some information from chinook, a database representing a digital media store, including tables for artists, albums, media tracks, invoices and customers. The question we want to ask is:
“What is the full name of the artist who recently released an album called ‘The Storm Before the Calm’ and are they in the FooBar database? If so, what albums of theirs are in the FooBar database and what is the total duration of all such albums?”
NOTE: we have called our database FooBar to give it a unique name. It can be set to anything else you may prefer at the time of defining the list of tools in the variable tools above.
Let us run this prompt through the MRKL system and see the thought-act-observe cycle the system goes through to produce the answer.
mrkl.run("""
What is the full name of the artist who recently released an album called
'The Storm Before the Calm' and are they in the FooBar database?
If so, what albums of theirs are in the FooBar database and what is the
total duration of all such albums?""")
### MODEL OUTPUT ###
> Entering new AgentExecutor chain...
I need to find out the artist's full name, if they are in the FooBar database, and the total duration of their albums in the database.
Action: Search
Action Input: "The Storm Before the Calm" artist
Observation: The Storm Before the Calm (stylized in all lowercase) is the tenth (and eighth international) studio album by Canadian-American singer-songwriter Alanis ...
Thought: I now need to check if Alanis Morissette is in the FooBar database.
Action: FooBar DB
Action Input: Is Alanis Morissette in the FooBar database?
> Entering new SQLDatabaseChain chain...
Is Alanis Morissette in the FooBar database?
SQLQuery: SELECT Name FROM Artist WHERE Name LIKE '%Alanis Morissette%';
SQLResult: [('Alanis Morissette',)]
Answer: Yes, Alanis Morissette is in the FooBar database.
> Finished chain.
Observation: Yes, Alanis Morissette is in the FooBar database.
Thought: I now need to find out what albums of hers are in the FooBar database and what is the total duration of all such albums.
Action: FooBar DB
Action Input: What albums of Alanis Morissette are in the FooBar database and what is the total duration of all such albums?
> Entering new SQLDatabaseChain chain...
What albums of Alanis Morissette are in the FooBar database and what is the total duration of all such albums?
SQLQuery: SELECT Album.Title, SUM(Track.Milliseconds) AS TotalDuration FROM Album INNER JOIN Track ON Album.AlbumId = Track.AlbumId WHERE Album.ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'Alanis Morissette') GROUP BY Album.Title;
SQLResult: [('Jagged Little Pill', 3450925)]
Answer: The albums of Alanis Morissette in the FooBar database are 'Jagged Little Pill' and the total duration of all such albums is 3,450,925 milliseconds.
> Finished chain.
Observation: The albums of Alanis Morissette in the FooBar database are 'Jagged Little Pill' and the total duration of all such albums is 3,450,925 milliseconds.
Thought: I now know the final answer.
Final Answer: Alanis Morissette is the artist who recently released an album called 'The Storm Before the Calm' and her albums in the FooBar database are 'Jagged Little Pill' with a total duration of 3,450,925 milliseconds.
> Finished chain.
"Alanis Morissette is the artist who recently released an album called 'The Storm Before the Calm' and her albums in the FooBar database are 'Jagged Little Pill' with a total duration of 3,450,925 milliseconds."As you can see the with integration of external search capability, database access and such other tools, you can build a very powerful application using LLMs as a natural language interface to interact with the system.
Finally we look at Self-Ask-With-Search which is about composability — getting language models to perform compositional reasoning tasks where the overall solution depends on correctly composing the answers to sub-problems. A comparison of this approach with the CoT is as given below:

As you can see, Self-Ask goes through breaking the original problem into sub problems, solving them separately and then combining all the intermediate answers to get the final answer. A code example of the same using langchain is given below. We will ask our model to answer — “Who was president of the U.S. when superconductivity was discovered?”
from langchain import OpenAI, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for searching"
)
]
self_ask_with_search = initialize_agent(tools, llm, agent="self-ask-with-search", verbose=True)
self_ask_with_search.run("Who was president of the U.S. when superconductivity was discovered?")The intermediate steps and web search the model goes through to arrive at the final answer is very interesting. It shows how the model breaks down the problem into smaller modular steps, using other tools to then get answers and combining all these answer to get the final answer.
> Entering new AgentExecutor chain...
Yes.
Follow up: When was superconductivity discovered?
Intermediate answer: 1911
Follow up: Who was president of the U.S. in 1911?
Intermediate answer: William Howard Taft was elected the 27th President of the United States (1909-1913) and later became the tenth Chief Justice of the United States (1921-1930), the only person to have served in both of these offices.
So the final answer is: William Howard Taft
> Finished chain.
'William Howard Taft'Conclusion
Large Language Models like the GPT3, ChatGPT etc have been under significant spotlight. Due to the narrative in media, people believe that these models are all knowing, very smart and can solve all kind of problems. However, such is not the case. These models have been trained on a very large web scale text data which allows them to learn to predict next word based on the string or words seen so far. These models have no other ability to do a mathematical or logical calculation or be factually correct. Prompt Enigneering tries to address this shortcoming by combining the LLMs with elaborate prompts, various external sources and tools.
In Yann LeCun’s words as per this tweet— “Yes, the need for prompt engineering is a sign of lack of understanding. No, scaling alone will not fix that.”
LLMs are expected get more and more capable, may be by leveraging some new approaches and may move beyond just being language modellers. This in turn may reduce the need for Prompt Engineering. However, till that happens, Prompt Engineering is here to stay with many new approaches likely to see the light of the day. Prompt Engineering is a high paying in-demand skill to have.
Code in this blog available at this repo — https://github.com/nsanghi/Prompt-Engineering-Intro