

1. Introduction
Reinforcement Learning (RL) is a sub topic under Machine Learning. It is one of the fastest growing disciplines helping make AI real. Combining Deep Learning with Reinforcement Learning has led to many significant advances that are increasingly getting machines closer to act the way humans do. All intelligent beings start with a small knowledge. However, as they interact with the world and gain experiences, they learn to adapt to the environment becoming better at doing things.
The modern concept of Reinforcement Learning is combination of two different threads through their individual development.
- First is the concept of optimal control especially the discipline of Dynamic Programming introduced by Richard Bellman in 1950. It is all about planning through the space of various options using Bellman recursive equations.
- The second thread is learning by trial and error which finds its origin in psychology of animal training. Edward Thorndike was the first one to express the concept of “trial and error” in clear terms. In his words:
In 1980’s these two fields merged together to give rise to the field of modern Reinforcement Learning. In last decade, with the emergence of powerful deep learning methods, reinforcement learning when combined with deep learning is giving rise to very powerful algorithms that could make Artificial Intelligence real in coming times.
1.1 Machine Learning Branches
Machine Learning involves learning from data presented to the system so that system can perform a specified task. The system is not explicitly told how to do the task. Rather, it is presented with the data and system learns to carry out some task based on a defined objective.
Machine learning approaches are traditionally divided into three broad categories as shown in Figure 1 below:
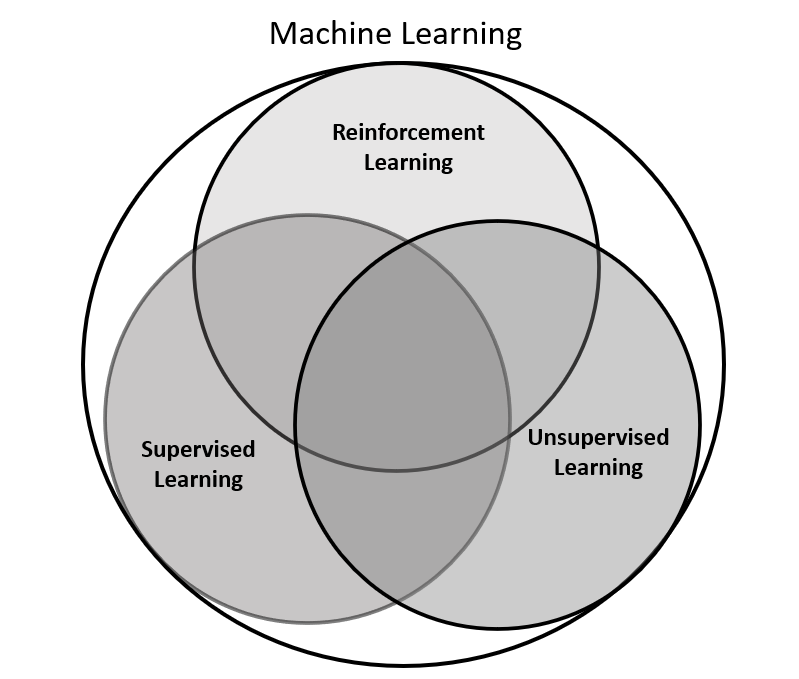
Figure 1: Branches of Machine Learning
The three branches of machine learning differ in the sense of “feedback” available to the learning system.
1.2 Supervised Learning
In Supervised Learning, the system is presented with the labelled data and the objective is to generalize knowledge so that new unlabeled data can be labelled. Consider that images of cats and dogs are presented to the system along with labels of which image shows a cat or a dog.
The input data is represented as a set of data [latex]D=\left(x_1,y_1\right),\left(x_2,y_2\right),\ldots\left(x_n,y_n\right)[/latex], where [latex]x_1,x_2,\ldots,x_n[/latex] are the pixel values of individual images and [latex]y_1,y_2,\ldots,y_n[/latex] are the labels of the respective images say value of 0 for an image of cat and value of 1 for image of a dog. The system takes this input and learns a mapping from image [latex]x_i[/latex] to label [latex]y_i[/latex]. Once trained, the system is presented with a new image [latex]x’[/latex] to get a prediction of the label [latex]y’[/latex] = 0 or 1 depending on whether the image is that of a cat or a dog. This is a classification problem where the system learns to classify an input into correct class. We have similar setup for regression where we want to predict a continuous output [latex]y_i[/latex] based on the vector of input values [latex]x_i[/latex].
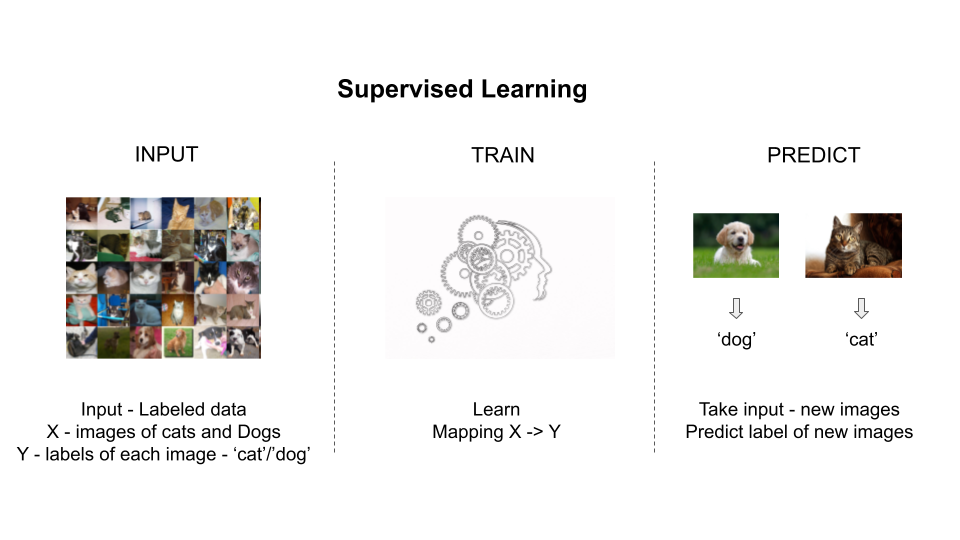
Figure 2: Supervised Machine Learning
1.3 Unsupervised Learning
The second branch is Unsupervised Learning. Unsupervised Learning has no labels. It only has the inputs [latex]D=x_1,x_2,\ldots,x_n[/latex] and no labels. The system uses this data to learn the hidden structure of the data so that it can cluster/categorize the data into some broad categories. Post learning, when the system is presented with a new data point [latex]x’[/latex], it can match the new data point to one of the learnt clusters. Unlike Supervised Learning, there is no well-defined meaning to each category. Once the data is clustered into category, based on most common attributes within a cluster we could assign some meaning to it. The other use of Unsupervised Learning is to use leverage underlying input data to learn the data distribution so that the system can be subsequently queried to produce a new synthetic data point.
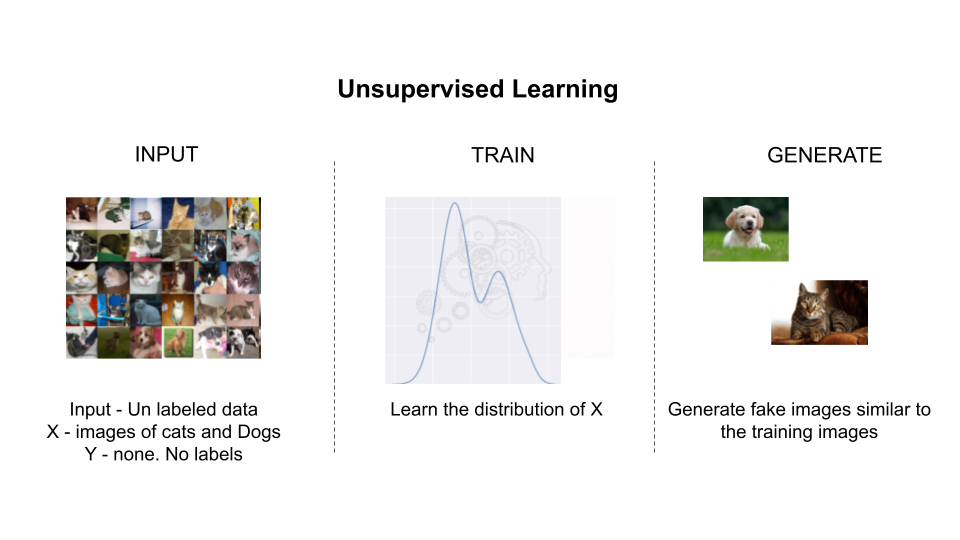
Figure 3: Unsupervised Machine Learning
1.4 Reinforcement Learning (RL)
While supervised Learning is learning with a teacher – the labelled data telling the system what the mapping form input [latex]x_i[/latex] to output [latex]y_i[/latex] is, RL is more like learning with a critic. The Critic gives feedback to the learner (the model) on how good or bad his knowledge is. The learner uses this feedback to iteratively improve its knowledge.
Let us first look at an example. Assume we are designing an autonomous vehicle which can drive on it own. We have a car which we will call agent i.e., a system or an algorithm that is leaning to drive on its own. It is learning a behavior to drive. It’s current coordinates, speed, direction of motion when combined together as a vector of numbers is known as its current state. The agent uses its current state to make a decision to either apply brake or press on gas pedal. It also uses this information to turn the steering to change the direction of car’s motion. The combined decision of “breaking/accelerating” and “steering the car” is known as action. The mapping of a specific current state to a specific action is known as policy. The agent’s action when good will yield a happy outcome and when action is bad, it will result in an unhappy outcome. Agent uses this feedback of outcome to assess the effectiveness of its action. The outcome as a feedback is known as reward that the agent gets for acting in a particular way in a specific state. Based on the current state and its action, the car reaches a new set of coordinates, speed and direction. This is the new state that the agent finds itself in based on how it acted in previous step. Who provides this outcome and decides the new state? It is the surroundings of the car and it is something that car/agent has no control over. This everything else that agent does not control is known as environment.
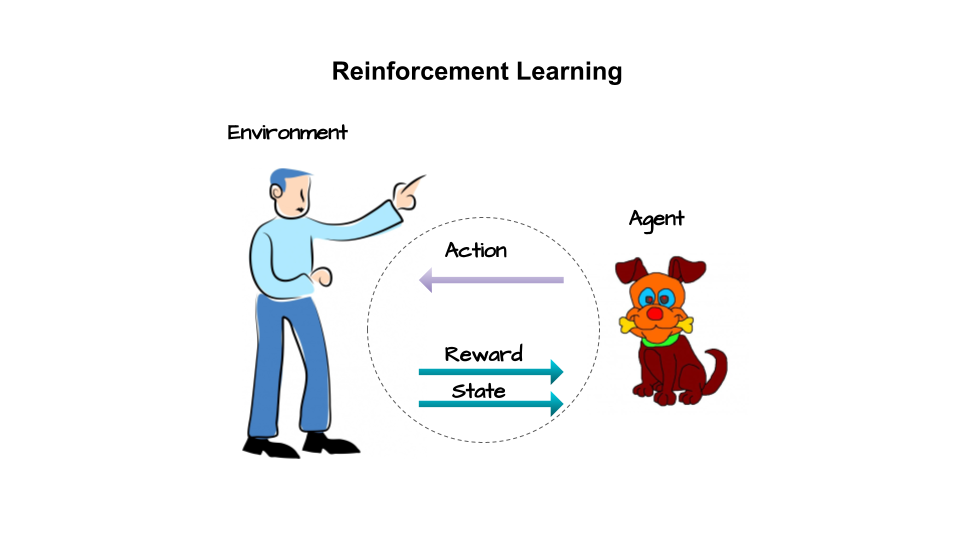
Figure 4: Reinforcement Learning
In Reinforcement Learning, the agent does not have prior knowledge of the system. It gathers feedback and uses that feedback to plan/learn actions to maximize a specific objective. As it does not have enough information about the environment initially, it must explore to gather insights. Once it gathers “enough” knowledge, it needs to exploit that knowledge to start adjusting its behavior in order to maximize the objective it is chasing. The difficult part is that there is no way to know when the exploration is “enough. If the agent continues to explore even after it has obtained perfect knowledge, it is wasting resources trying to gather new information of which there is none left. On the other hand, if the agent prematurely assumes that it has gathered enough knowledge it may land up optimizing based on incomplete information and may perform poorly. This dilemma of when to explore and when to exploit is the core recurring theme of Reinforcement Learning algorithms.
In 2014, DeepMind, successfully combined Deep learning techniques with Reinforcement Learning to train a game playing agent which could play Atari games based on the images of the game without any prior knowledge of the rules of the Atari games.
To motivate further, let us look at some examples of how RL is being used today:
- Autonomous Vehicles (AV) : AVs have sensors like LiDAR, Radar, Cameras etc., using which AVs sense their nearby environment. The raw sensory data and object detection is combined to get a unified scene representation which is used for planning out a path to destination. Actions like overtaking, lane changing, Automated parking also leverage various parts of reinforcement learning to build intelligence into the behavior. The alternative would be to hand craft various rules and that can never be exhaustive or flexible.
- Robots : Using Computer vision and Natural Language Processing or Speech recognition using Deep Learning techniques have added human like perceptions to autonomous robots. Further, deep learning and reinforcement learning combined methods have resulted in teaching robots to learn human like gaits to walk, pick and manipulate objects or to observe human behavior through cameras and learn to perform like humans.
- Recommendation Systems : Today we see recommender systems everywhere. Video sharing/hosting applications such as YouTube and Facebook suggest us the videos that we would like to watch based on our viewing history. All such recommender engines are increasing getting driven by Reinforcement Learning based systems. These systems continually learn from the way users respond to the suggestions presented by the engine. A user acting on the recommendation reinforces these actions as good actions given the context.
- Finance and Trading : Due to its sequential action optimization focus wherein past states and actions influence the future outcomes; Reinforcement Learning finds significant use in time series analysis especially in the field of Finance and Stock Trading. Many automated trading strategies use reinforcement learning approach to continually improve and fine tune the trading algorithms based on the feedback from past actions.
- Game Playing : Finally, RL based agents are able to beat human players in many a board games. While it may seem wasteful to design agents that can play games, there is a reason for that. Games offer a simpler idealized world, making it easier to design, train and compare approaches. Approaches learnt under such idealized environment/setup can be subsequently enhanced to make agents perform well in real world situations. Games provide a well-controlled environment to research deeper into the field.
2. Types of algorithms/approaches in RL
Let us briefly look at the core elements that comprise a RL system:
Policy is what forms the intelligence of the agent. An agent gets to interact with the environment to sense the current state of the environment e.g., robot getting visual and other sensory inputs from the system. The robot, like an intelligent entity, uses the current information to decide on what to do next i.e., what action to perform. Policy maps the state to the action. Policies can be deterministic i.e., for a given state of environment, there is a fixed action that the agent takes. Sometimes the policies can be stochastic i.e. for a given state there are multiple possible actions that the agent can take.
Reward refers to the goal/objective that agent is trying to achieve. Consider a robot trying to go from Point A to Point B. It senses the current position and takes an action. If that action brings it near to its goal B, we would expect the reward to be positive. If it takes the robot away from Point B, it is an unfavorable outcome and we would expect the reward to be negative. Reward is a numerical value indicating the goodness of the action taken by the agent and is the primary way for agent to adjust its behavior i.e., optimizing the policy that it is learning.
Value functions are like long term rewards which are influenced not only by the environment but also by the policy agent is following. Value exists because of reward. The agent accumulates the reward as it follows a policy and uses this cumulative reward to assess the value in a state. It then makes changes to its policy to increase the value of the state.
The last component is model of the environment. In some approaches of finding optimal behavior, agents use the interactions with the environment to form an internal model of the environment. Such an internal model helps the agent to plan i.e., consider one or more chain of actions to assess the best sequence of actions. This method is called model-based learning. At the same time there are other methods which are completely based on trial-and-error. Such methods do not form any model of the environment. Hence these are called model-free methods. Majority of the agents use a combination of model-based and model-free methods for finding optimal policy.
With the background of reinforcement learning setup and bellman equations, it is time to look at the landscape of algorithms in reinforcement learning world. Figure 5 shows a high-level landscape of the various types of learning algorithm in RL space.
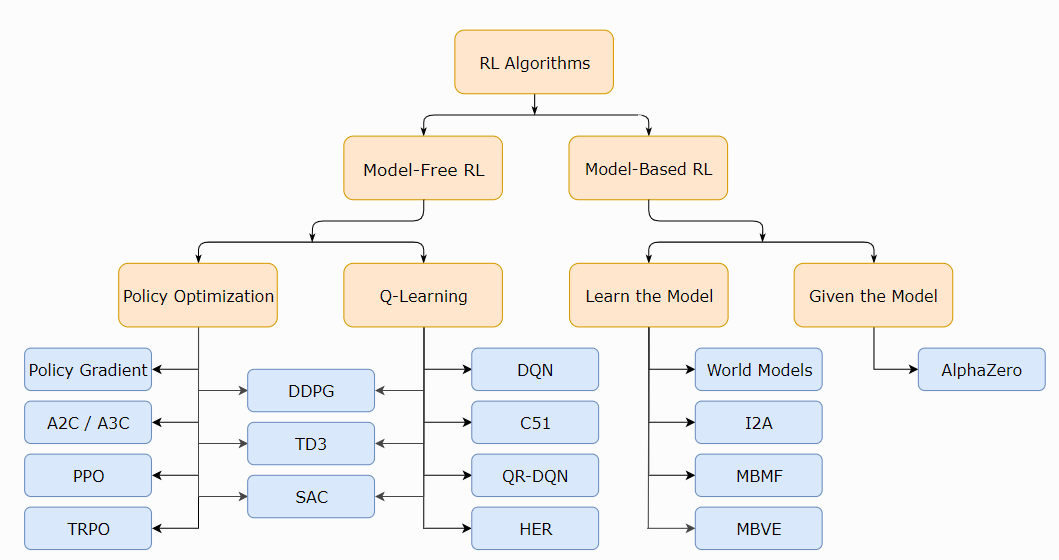
Figure 5: Mind map of algorithms in reinforcement learning. It is a high level map showing only broad categorization.
The first broad categorization of algorithms can be done base on the knowledge (or lack thereof) of the model – i.e. category of model based and model free algorithms.
Model based algorithms can be further classified into two categories – one where we are given the model e.g. game of “Go” or “chess” and second category being the one where agent needs to explore and learn the model. Some popular approaches under “learn the model” are World models, Imagination Augmented Agents (I2A), Model Based RL with Model Free Fine Tuning (MBMF) and Model Based Value Exploration (MBVE).
Moving back to “model free” setup, There is a set of algorithms that directly optimize the policy to maximize the long term cumulative reward. Some popular ones under this category are Policy gradient, Actor Critic and its variations (A2C / A3C), Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO).
There is another set of algorithms that use Bellman Dynamic Programming to learn the quality of a random policy and then use value functions to iteratively improve the policies. Q-learning forms the major part of model free bellman driven state/action value optimization. The popular variants under this approach are Deep Q-Networks (DQN) along with its various variants, Categorical 51-Atom DQN (C51), Quantile Regression DQN (QR-DQN) and Hindsight Experience Replay (HER).
Finally, there are a set of algorithms which lie midway between Q-learning and Policy optimization. The popular ones in this category are Deep Deterministic Policy Gradient (DDPG), Twin delayed DDPG (TD3) and Soft Actor-Critic (SAC).
Above categorizations are just to help you appreciate the different approaches and popular algorithms. However, the list and the categorization are not an exhaustive one. The field of reinforcement learning is evolving rapidly with new approaches being added on a regular basis. Please use above mind map only as a high-level guidance.
3. How to get started
Like any other discipline of Machine Learning, mastering RL involves two aspects: theory and algorithm implementations. I will first walk through the book that I have written which forms an end-to-end learning product for mastering RL. Next, I will present some alternate sources, courses and books by the leading experts from various top universities and research institutions.
3.1 Follow my Book – Deep Reinforcement Learning with Python
You can checkout the details here
I have written a book which covers all the aspects of RL combined with Deep Learning which covers the theory and implementations right from the very basic algorithms to the advanced ones as shown in the mind map in Figure 2. It takes a linear approach to go deeper into all the various RL setups and popular algorithms under each branch. It is getting ready to be published in coming April.
Though this book assumes no prior knowledge of the field of Reinforcement Learning, it expects the readers to be familiar with basics of Machine Learning specifically Supervised Learning. Have you coded in Python earlier? Are you comfortable working with libraries like NumPy and scikit-learn? Have you heard of deep learning and have explored basic build blocks of training simple models in PyTorch or TensorFlow? You should answer yes to all of the above questions to get the best out of this book. If not, I would suggest you to refresh these concepts first, nothing too deep, any introductory online tutorial or book from Apress on above topics would be sufficient.
For a subject like this, math is unavoidable. However, I have tried my best to keep it minimal. The book quotes a lot of research papers giving short explanations of the approach taken. Readers wanting to have a deeper understanding of the theory should go through these research papers. This book’s purpose is to introduce practitioners to the motivation and high-level approach behind many of the latest techniques in this field. However, by no means it is meant to provide a complete theoretical understanding of these techniques which is best gained by reading the original papers.
The book is organized into ten chapters.
Chapter 1 – Introduction to Reinforcement Learning, is an introduction to the topic, setting the background and motivating readers with real world examples. It also covers the installation of python and related libraries to be able to run the code accompanying this book.
Chapter 2 – Markov Decision Processes, defines the problem in detail that we want to solve in RL. It goes in depth about what constitutes a reward, value functions, model and policy. It introduces various flavors of Markov Processes, establishing the equations by Richard Bellman as part of Dynamic Programming.
Chapter 3 – Model based Algorithms, focusses on the setup in which model is given and the agent plans its action for optimal outcome. It introduces OpenAI Gym environment library that is used for coding and testing algorithms throughout the book. Finally, it explores value and policy iteration approaches to planning.
Chapter 4 – Model Free Approaches, talks about the model free learning methods. Under this setup, the agent has no knowledge of the environment/model. It interacts with the environment and uses the rewards to learn an optimal policy through trial-and-error approach. It specifically looks at Monte Carlo (MC) approach and Temporal Difference (TD) approach to learning, first studying these individually and then combining the two under the concept of n-step returns and eligibility traces.
Chapter 5 – Function Approximation and Deep Learning, moves to looking at setups in which the state of the system changes from being discrete (as will be the case till chapter 4) to being continuous. Next, it explores the concept of using parameterized functions to represent the state and bring scalability- First using the traditional approach of hand-crafted function approximation followed by use of Deep Learning based model as non-linear function approximators.
Chapter 6 – Deep Q Learning (DQN), dives deep into the approach DeepMind took to successfully demonstrate the use of deep learning together with reinforcement learning designing agents that could learn to play video games such as Atari Games. It explores how DQN works and what tweaks are required to make it learn. It is followed by a survey of various flavors of DQN, complete with detailed code examples, both in PyTorch and TensorFlow.
Chapter 7 – Policy Gradient Algorithms, switches the focus to explore the approach of learning a good policy directly in model free setup. The approaches in preceding chapters are based on first learning value functions and then using these value functions to optimize the policy. In this chapter, we first talk about the theoretical foundations of the direct policy optimization approach. After establishing the foundations, we discuss various approaches including some very recent and highly successful algorithms, complete with implementations in PyTorch and TensorFlow.
Chapter 8 – Combining Policy Gradients and Q-Learning, as the name suggests, deals with approach of combining value based DQN and Policy Gradients methods in order to leverage the advantages of both the approaches. It also enables us to design agents that can operation in continuous action spaces We specifically look at three very popular approaches – Deep Deterministic Policy Gradients (DDPG), Twin Delayed DDPG (TD3), Soft Actor Critic (SAC). Like before, comprehensive implementations in PyTorch and TensorFlow is provided to help readers master the subject.
Chapter 9 – Integrated Planning and Learning, is all about combing the model-based approach from Chapter 3 and model free approach from Chapters 4 to 8. It explores the general framework under which such integration can be made possible. Finally, it explains Monte Carlo Tree Search (MCTS) and how the same was used to train AlphaGo that could beat export human Go Players.
Chapter 10 – Further Exploration and Next Steps, surveys various other extensions of Reinforcement Learning, concepts like scalable model-based approaches, Imitation and Inverse Learning, Derivative free methods, Transfer and Multi Task Learning as well as Meta Learning. The coverage here is at 30,000 feet to expose readers to new and related concepts without getting lost into the details. The chapter concludes by talking about the way readers should continue to explore and learn beyond what is covered in this book.
3.2 Other courses and links
Lastly, I present list of courses and links that can help you further explore the theory and advanced topics. I cite them below in no particular order:
- Text Book – Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto. This is a must read for any practitioner of RL. The book is divided into 3 parts and I would strongly recommend reading through Parts I and II. The sections marked with (*) can be skipped in first reading. And if you click on this, you will see the links of python and Matlab implementations of the examples and exercises contained in the book.
- Video Lectures by David Silver. These lectures are wonderful and easy to understand introduction to RL, the basics and some advanced topics. I highly recommend watching these in a sequential manner.
- Deep RL Course by Assistant Professor Sergey Levine of UC Berkeley. As of now you have complete set of video lectures, slides and python assignments available for the Fall 2020 offering. It goes deeper into derivations and have significant math. However, if you have a good background on Linear Algebra, Probability theory and Calculus, it would be very rewarding to go through this material.
- Reinforcement Learning Specialization at Coursera offered by University of Albera, the same university where Sutton and Barto are Professors at.
- Deep RL Bootcamp – 2017. These are video recordings of a 2 day bootcamp in 2017 organized at UC Berkeley by Professor Pieter Abbeel. A good set of video recordings with a decent overlap with the material covered in Sergey Levine’s course.
- Stanford’s Reinforcement Learning Course. Again an excellent introduction to the field of Reinforcement Learning. While the material is available for currently underway Winter 2021 run of the course, complete with presentations, notes and assignment, the videos are not available for free viewing. You can checkout the videos of 2019 run here.
- Practical Reinforcement Learning Course by HSE University Moscow. It is a very well paced course covering the basics to advance topics. However, at times I found the coverage of material to be a bit too high level for my likings. Their coding exercises are great though. Yon can also check out their latest iteration of the course at github.
- Advanced Deep Learning and Reinforcement Learning taught by DeepMind Scientists at University College London (UCL). It also covers the fundamentals and advance topics. The material has good overlap with the material covered in David Silver’s video lectures.
- Spinning Up in Deep RL, a web page with a python library hosted by OpenAI which is yet another great resource to dive deep into RL. In my view this material is a great resource to cement your understanding after going through the basic courses. Or you could dive right into it if you are comfortable with Deep Learning and PyTorch or TensorFlow.
4. Conclusion
Reinforcement Learning is seeing significant advances. There is more to the basic RL which I cover in my book’s last chapter. There are evolving disciplines like Imitation and Inverse Learning, Derivative free methods, Transfer and Multi Task Learning as well as Meta Learning.
RL is finding increasing use in very diverse applications ranging from Health Care, Autonomous Vehicles, Robots, Finance and e-commerce as well as various other fields.
In this blog I have tried to introduce the field of RL and also share links to various online resources that could be used to master this field.
I will be very happy to get your feedback so that I could improve it further.